What is the RAM model, and what are the best, worst, and average-case complexity of algorithms?
This post provide an introductory overview of the RAM model, the best, worst and average-case complexity of algorithms. It serves as my personal documentation of what I have learnt about algorithms, and I hope it will be beneficial to your own development as well.
What is the RAM model of computation?
The RAM (Random Access Machine) model is a theoretical model of computation used in computer science to evaluate the time complexity of algorithms. While it simplifies the complexity of real computers, the RAM model remains a valuable tool for algorithm analysis and design due to its simplicity and its ability to capture the fundamental aspects of computation.
The key aspect of the RAM model is that each type of operation requires a specific number of steps:
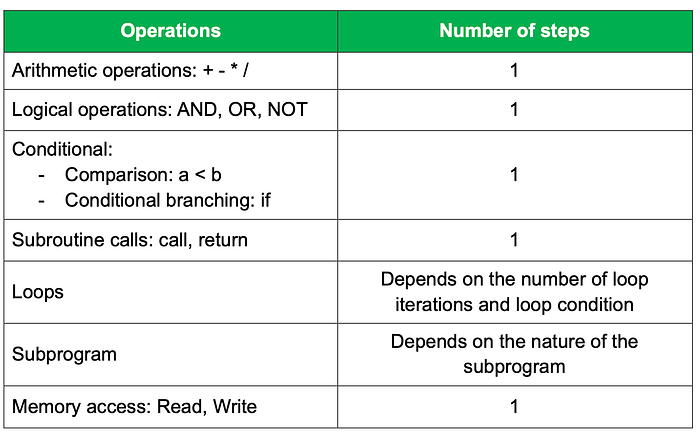
Under the RAM model, the time complexity of an algorithm is measured by counting the number of steps the algorithm needs to solve a problem instance. Assuming the RAM model can execute a fixed number of steps per second, we can convert the number of steps of the algorithm to actual running time, which allows us to determine the best-case, worst-case and average-case time complexity of algorithms.
What are the best, worst and average-case complexity of algorithms?
When we plot a graph with the problem-instance size(n) on the x-axis and the algorithm’s computational steps required to solve these instances on the y-axis, we get the following visualization:
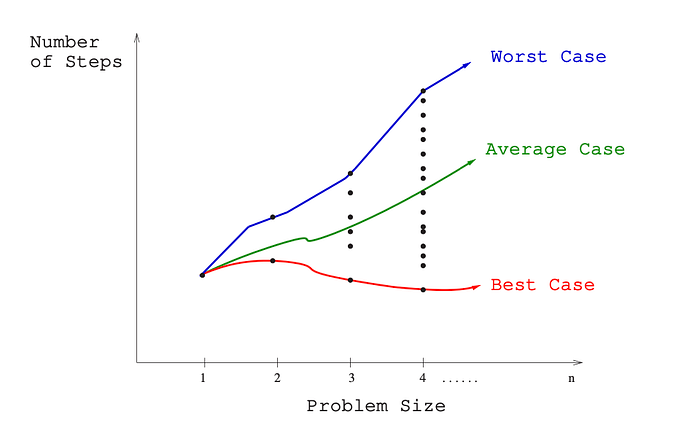
As the graph illustrates, the number of steps required to solve identical problem instances can fluctuate. This is because the content and arrangement of elements in the problem instance can affect the algorithm’s performance.
For example: a linear search will take less time to find and return the number 3 in this array [3, 2, 1] than in the array [1,2,3], even though the two arrays have the same size. This is because the number 3 is closer to the beginning of the first array.
- Worst-case complexity: A function that is defined by the maximum number of steps taken to solve any problem instance of size n.
- Best-case complexity: A function that is defined by the minimum number of steps taken to solve any problem instance of size n.
- Average-case complexity: A function that is defined by the average number of steps taken to solve any problem instance of size n.
Here are the best, worst and average case of a linear search for a array of size 3:
- Best-case complexity: 1. This occurs when the target element is the first element of the array. This means the search algorithm terminates after only one comparison.
- Worst-case complexity: 3. This occurs when the target element is the last element of the array or is not in the array at all. In both cases, the search algorithm will need to compare the target element with all 3 elements in the array.
- Average-case complexity: 2. This occurs when the target element is randomly distributed in the array.
Of the three notions to measure time complexity, worst-case complexity is most useful in algorithm analysis. This is because when selling a software product to a client, it is more convincing and practical to tell them that your product will take at most this much time to solve their problem, even in the worst case.
Since the best, worst and average-case complexity are defined as numerical functions, it can be difficult to to define them precisely, as they depend on the details the algorithm implementation. To simplify, we use the concept of Big O notation to analyze the algorithm’s complexity. The concept of Big O notation will be discussed in my next post.
Reference:
The information in this post is largely based on the book: The Algorithm Design Manual. Please check out the book for more details.
Subscribe to my Medium: https://medium.com/@exploreintellect/subscribe